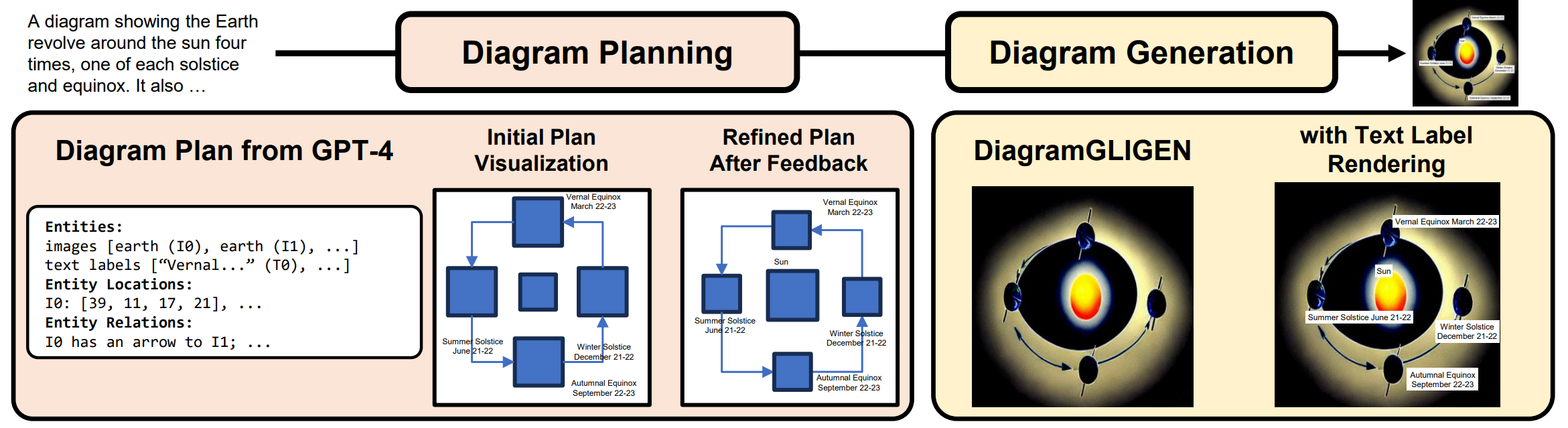
Qualitative Examples & Analysis
Comparison with Baselines
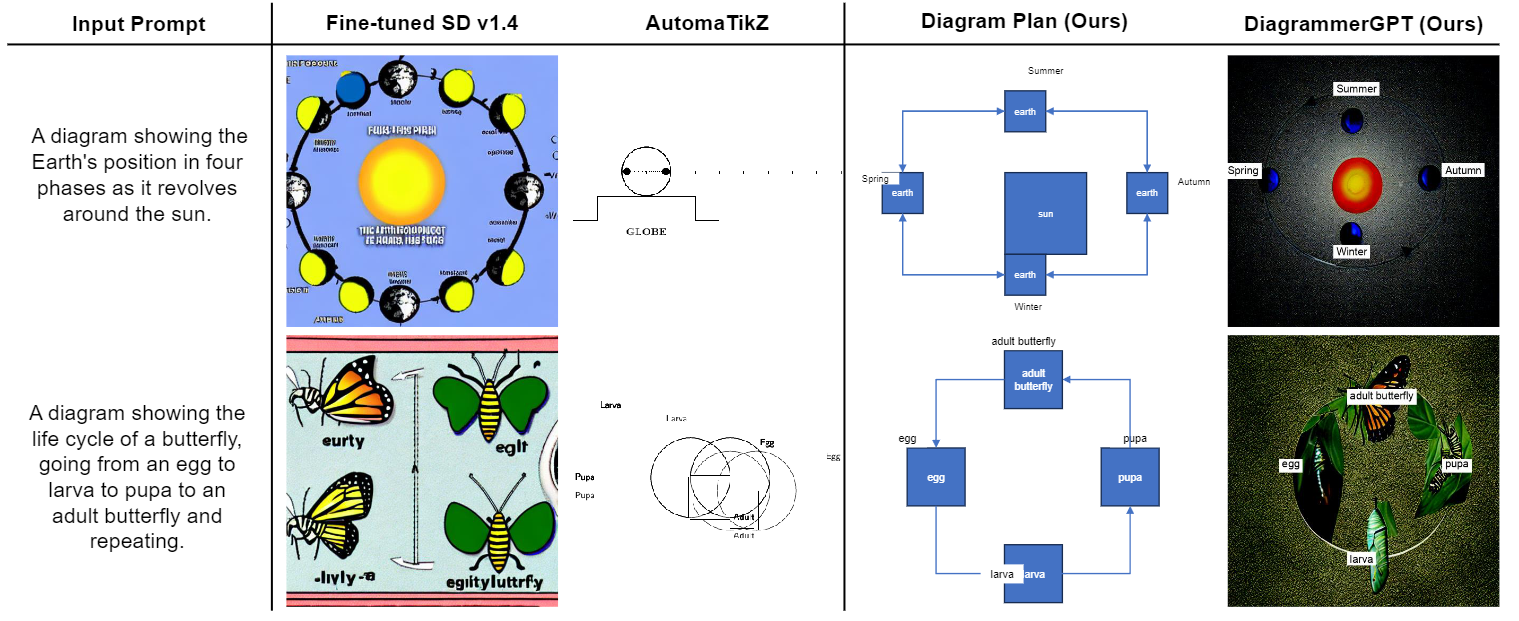
Figure 5. Example diagram generation results from baselines (fine-tuned Stable Diffusion v1.4 and AutomaTikZ) and our DiagrammerGPT
(both diagram plan and final diagram) on the AI2D-Caption test split. In the first example, our DiagrammerGPT correctly gets the object
count right and has clear text, whereas Stable Diffusion v1.4 overpopulates the entities orbiting around the sun. In the second example, our
DiagrammerGPT generates a quite accurate diagram plan (with all required elements) and a diagram that mostly reflects the plan, whereas
Stable Diffusion v1.4 fails to show a life cycle (i.e., missing the egg, pupa, and larva). As noted in Sec. 5.2, once a better backbone becomes
available, our DiagrammerGPT can produce better diagrams based on the diagram plans. AutomaTikZ struggles to generate the proper
layouts and objects for both examples.
Fig. 5 shows example diagrams generated by the baselines (Stable Diffusion v1.4
and AutomaTikZ) and our DiagrammerGPT (both diagram
plan and final generation diagram) on the AI2D-Caption test
split. Our diagram plans strongly reflect the prompts and
the final diagrams are more aligned to the input prompts. In
Fig. 5 top example, our diagram correctly shows the earth in
four phases revolving around the sun and in the second example, our diagram plan correctly represents the life cycle
of a butterfly and the generated diagram captures the circular flow of the diagram plan as well most aspects of the life
cycle. Stable Diffusion v1.4 either over- or under-generates
objects in the image (e.g., too many earths in the first example and missing egg/larva/pupa stages in Fig. 5 bottom
example), and AutomaTikZ fails to generate proper layouts
and objects. Although our generated diagram plans are generally correct, however, sometimes DiagramGLIGEN can
fail to properly follow all aspects (e.g., the egg is misdrawn
and the larva/pupa are swapped in Fig. 5 bottom example).
As noted in Sec. 5.2, once a better backbone becomes available, our DiagramGLIGEN can produce better diagrams
following the diagram plans.
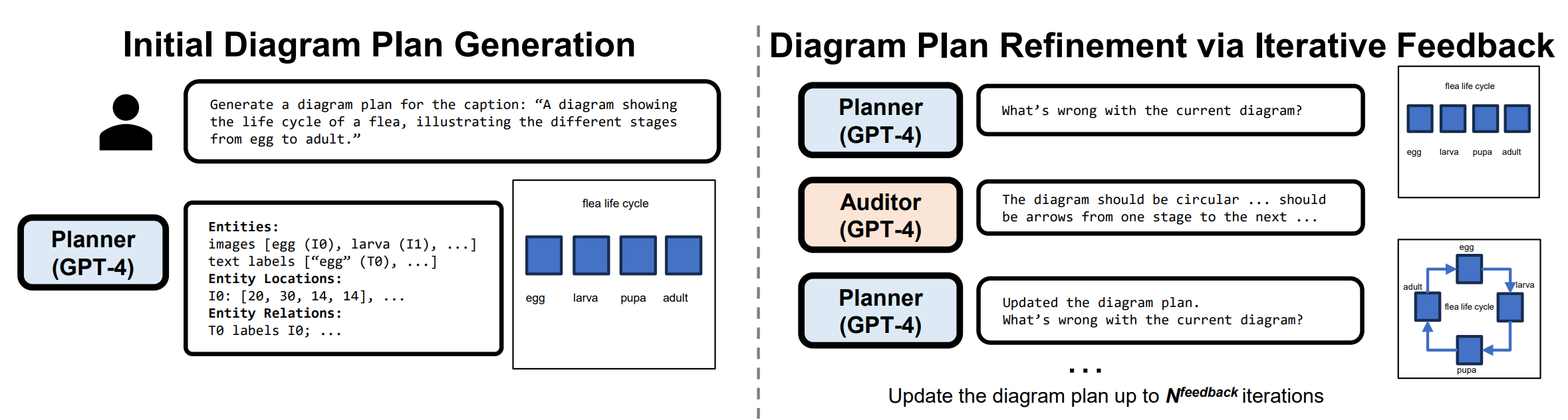
Diagram Plan Refinement
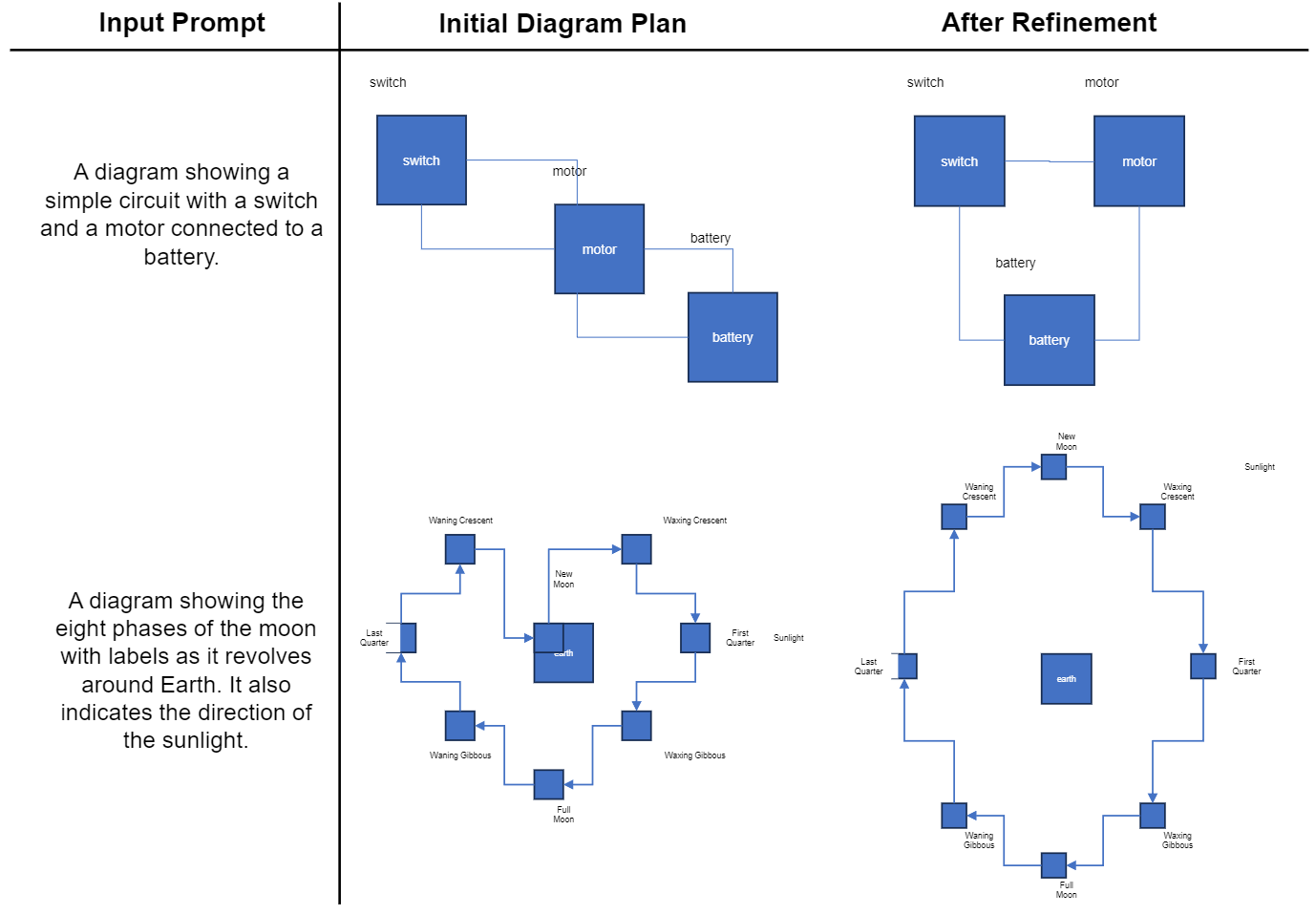
Figure 6. Examples from our diagram refinement step. Our auditor LLM can help reorganize the connections between the components to
be more clear in the first example and prevent overlaps of objects in the second example
In Fig. 6, we show how our
diagram refinement step (see Sec. 3.1) improves the diagram plans. In the top example, the switch is not connected
to the battery, thus does not affect the circuit. After refinement, the connections are corrected so the switch is now
also connected to the circuit and the layouts are adjusted
to have a more straightforward flow. In the bottom example, the moon phase of 'New Moon' is too low and overlaps
with the 'Earth' object. After refinement, there is no more
overlap.
Open-Domain Diagram Generation
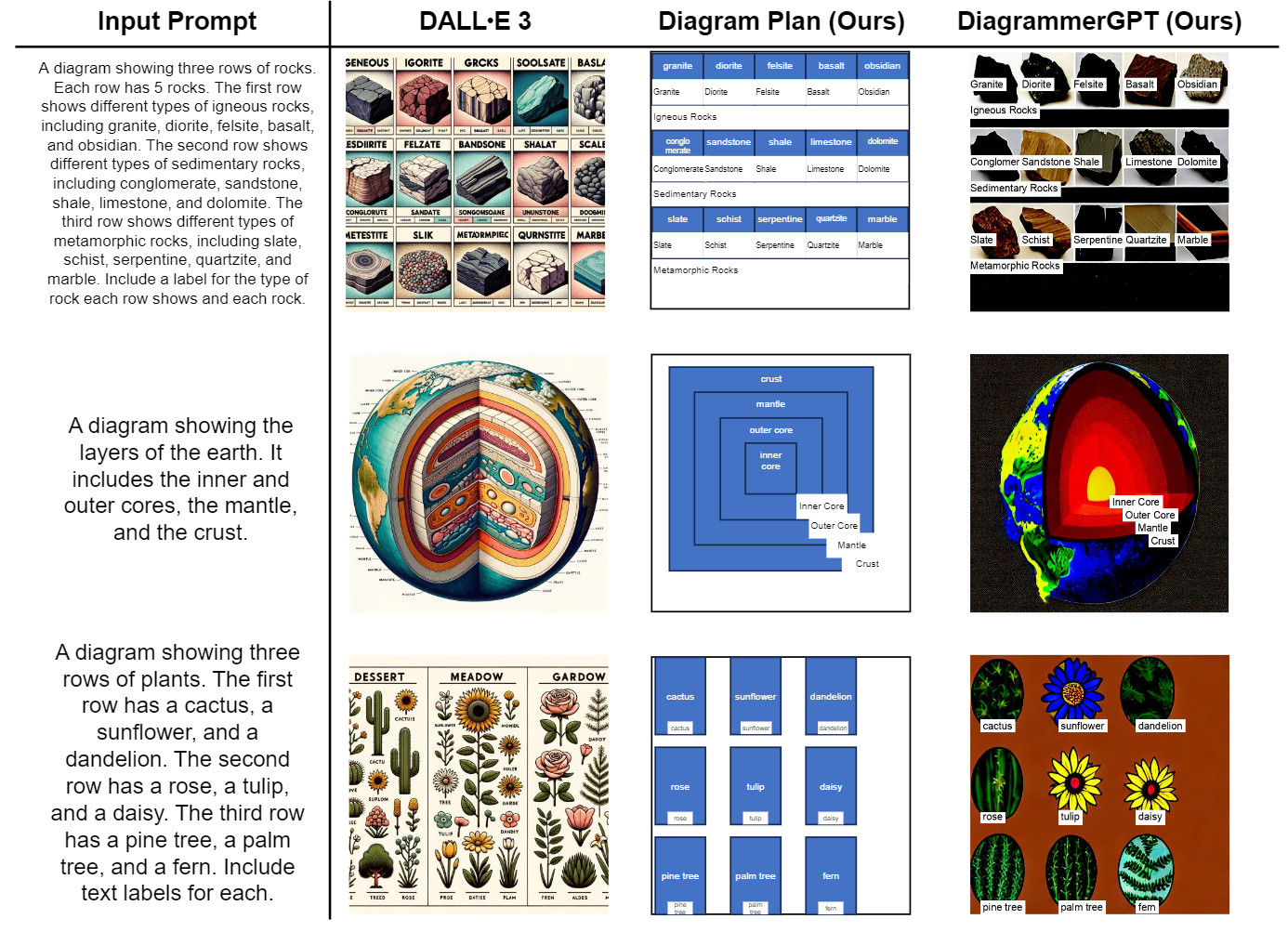
Figure 7. Examples of open-domain generation demonstrate that our DiagrammerGPT can create diagrams that adhere to the input text
prompts. Although DALL-E 3 yields images with superior visual quality, it tends to generate diagrams with redundant and crowded objects
and also struggles to follow the prompt accurately (e.g., in the second example, it is not clear where the locations of layers such as the
'inner core', 'outer core', and 'mantle' are. In the third example, it generates too many objects that are not in rows).
In Fig. 7, we demonstrate that our planner LLM can extend its capabilities to domains beyond the three specific
areas (astronomy, biology, and engineering) for which we
have in-context examples. As shown in the figure, our planner LLM generates fairly accurate layouts. While our DiagramGLIGEN struggles in some cases, it is able to strongly
adhere to the diagram plan. As mentioned in Sec. 5.2,
once a stronger layout-guided image generation model than
GLIGEN with Stable Diffusion v1.4 backbone is available,
our DiagrammerGPT can produce higher quality results.
In Fig. 7, we also compare the recently released DALL-E
3 model. We find that DALL-E 3 generally produces
images with good aesthetic style but tends to generate diagrams with redundant and crowded objects (e.g., excessive
unnecessary text descriptions in the rock and Earth examples, and an overabundance of plants in the third example).
It also continues to struggle with creating accurate diagrams
that adhere to a prompt (e.g., generating incorrect layers in
the earth example and generating three columns of plants
instead of three rows in the plant example). The DALL-E 3
system card also notes that DALL-E 3 tends to generate
scientifically inaccurate information in diagrams
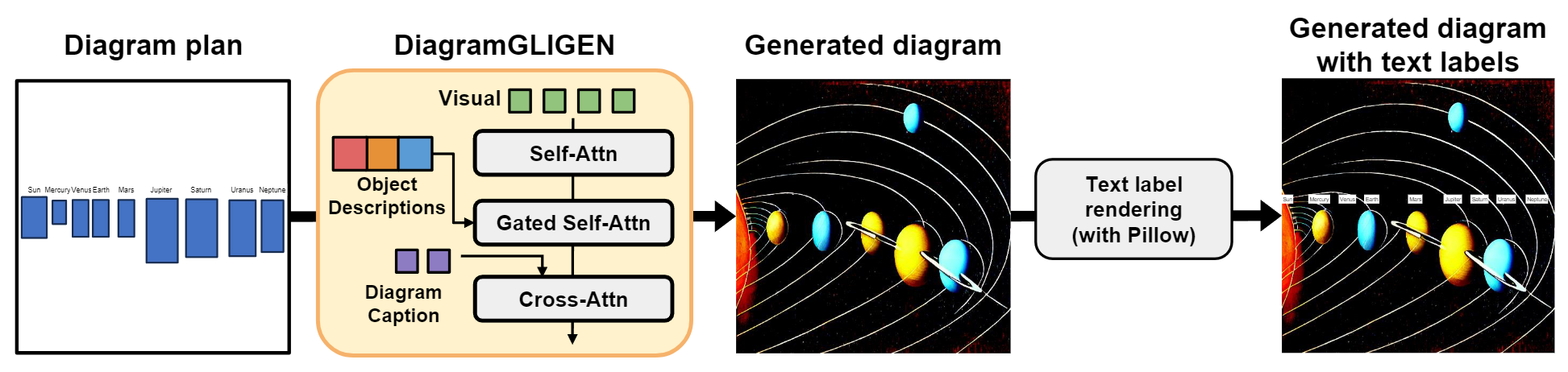
Vector Graphic Diagram Generation in Different Platforms
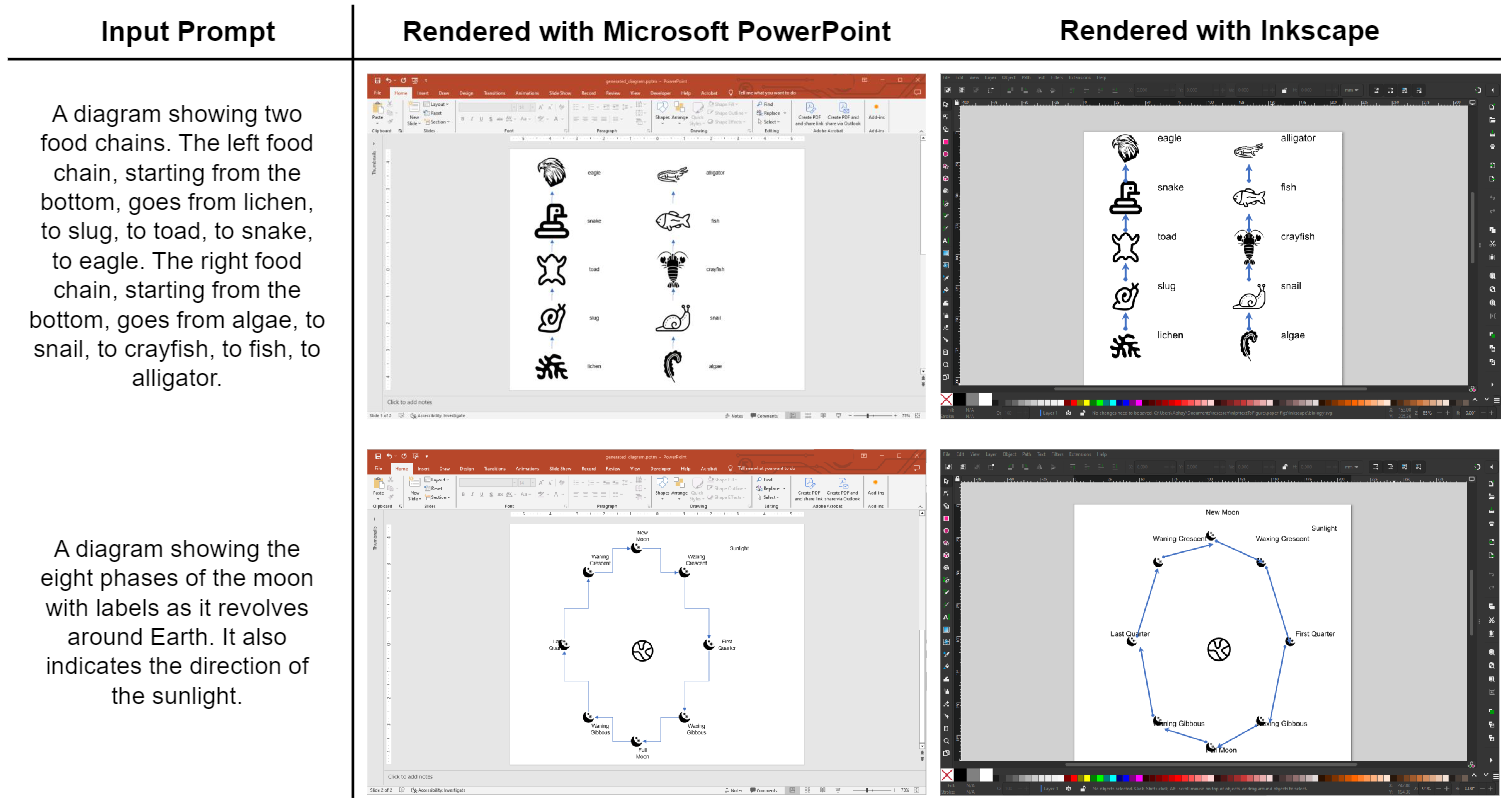
Figure 8. Examples of vector graphic diagrams generated with our diagram plans
and exported into Microsoft PowerPoint and Inkscape (with icons from Noun Project Icons API).
Although our primary focus is on a pixel-level diagram generation pipeline with DiagramGLIGEN, our diagram plans can also facilitate the creation of vector graphic
diagrams. These diagrams afford users significant flexibility for further edits and personalization of their diagram
layouts, such as changing colors, fonts, and object positions, or altering the diagram size without degrading quality. To achieve this, we render
our diagram plans in PowerPoint via VBA language
and in
Inkscape via a Python scripting extension (see Fig. 8).
While we experiment with these two platforms, our diagram plans can
be flexibly exported to any platform that supports script integration. In both platforms, we integrate features for text
and arrows/lines to delineate object text labels and relationships respectively. We represent objects using icons, which
are retrieved via the Noun Project Icons API based on corresponding text descriptions.
Human-in-the-Loop Diagram Plan Editing
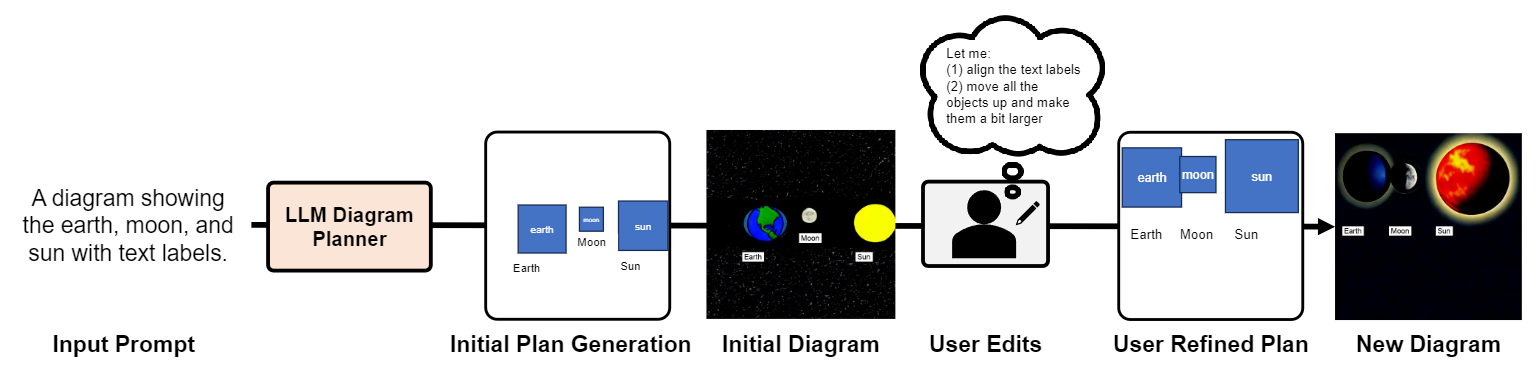
Figure 9. An illustration of human-in-the-loop diagram plan editing. Our DiagrammerGPT first provides an initial diagram plan with the
corresponding generated diagram, users can then review the generated layouts/diagrams and make adjustments based on their needs. With
the user-refined diagram plan, our DiagramGLIGEN creates diagrams that better suit the users' requirements
With the diagram plans being rendered in vector graphic platforms, as
mentioned above, our DiagrammerGPT can provide an editable diagram plan, allowing for human-in-the-loop editing. As illustrated in Fig. 9,
our framework first generates an initial diagram plan along with the rendered image.
Users can then review the generated layouts/diagrams and
make adjustments based on their needs/wants (e.g., move the objects, add/remove objects, adjust object sizes, etc.).
With the human-refined diagram plan, users can either keep
it in vector format and use icons (as mentioned in the previous paragraph) or give it back to DiagramGLIGEN and
then create pixel-level diagrams, resulting in diagrams/layouts that are better suited to end-users requirements.