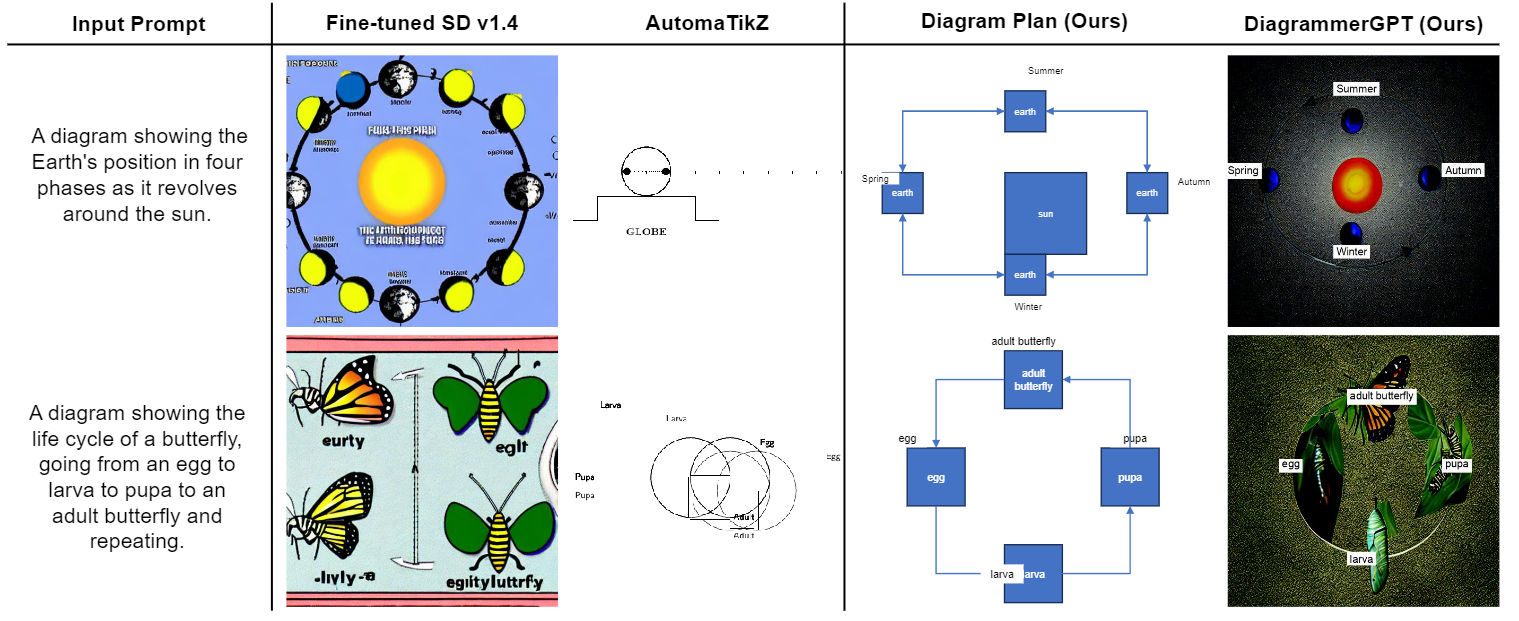
Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels.
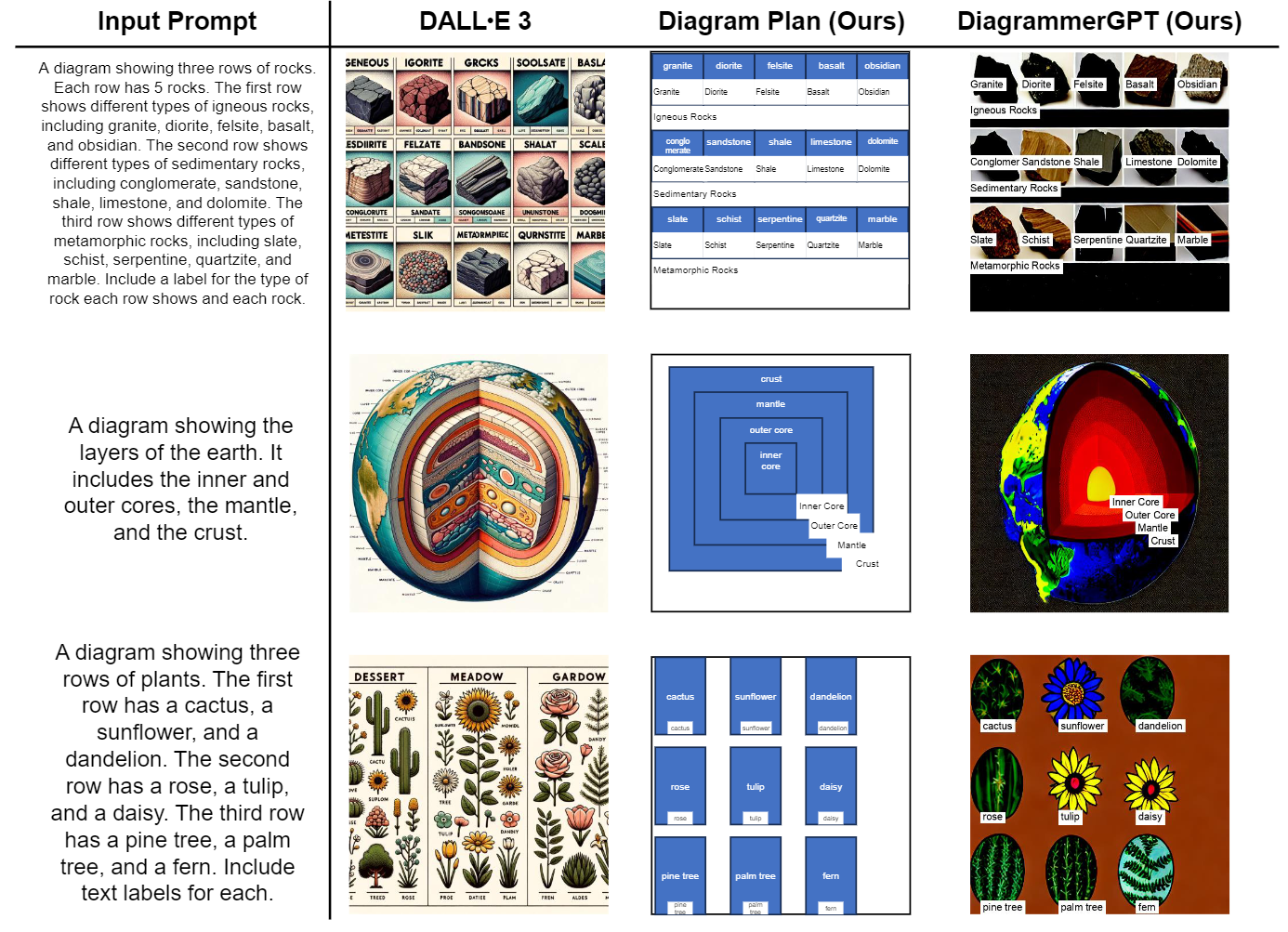
To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision).
We hope that our work can inspire further research on the diagram generation capabilities of T2I models and LLMs.
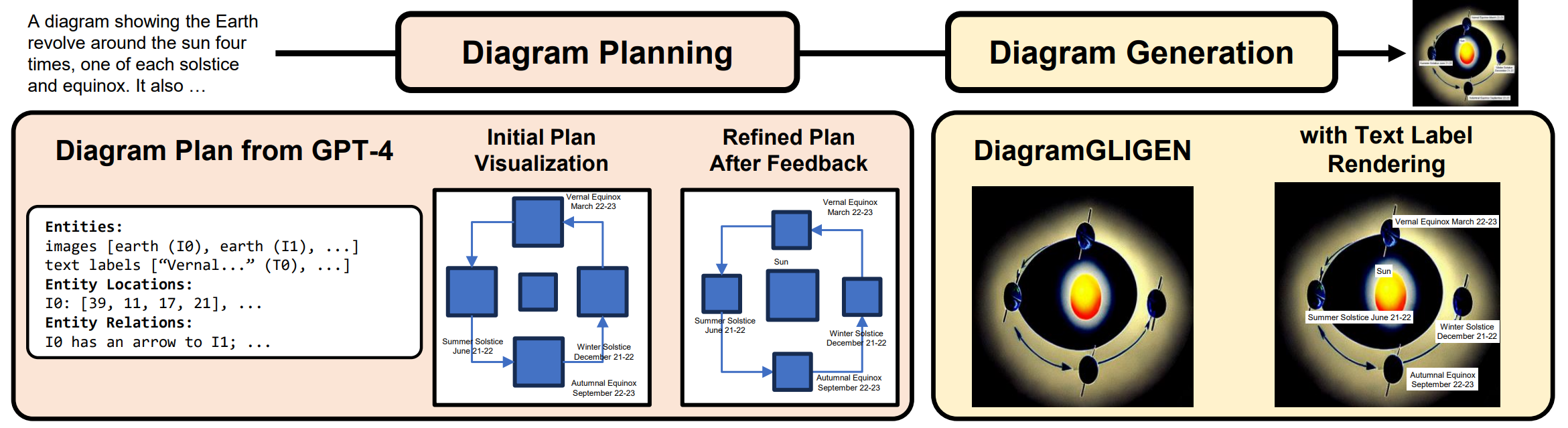
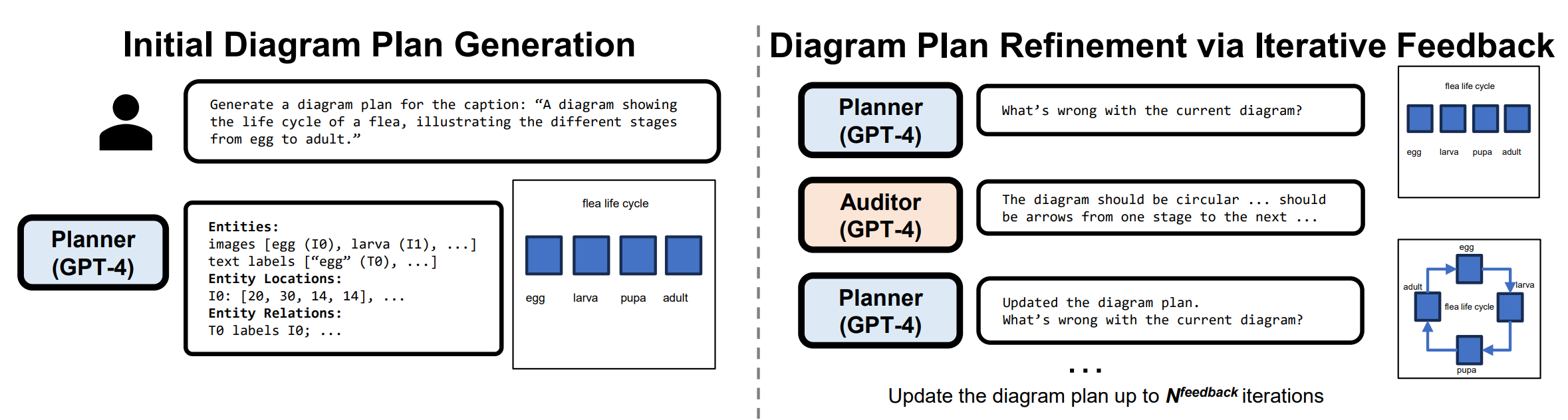
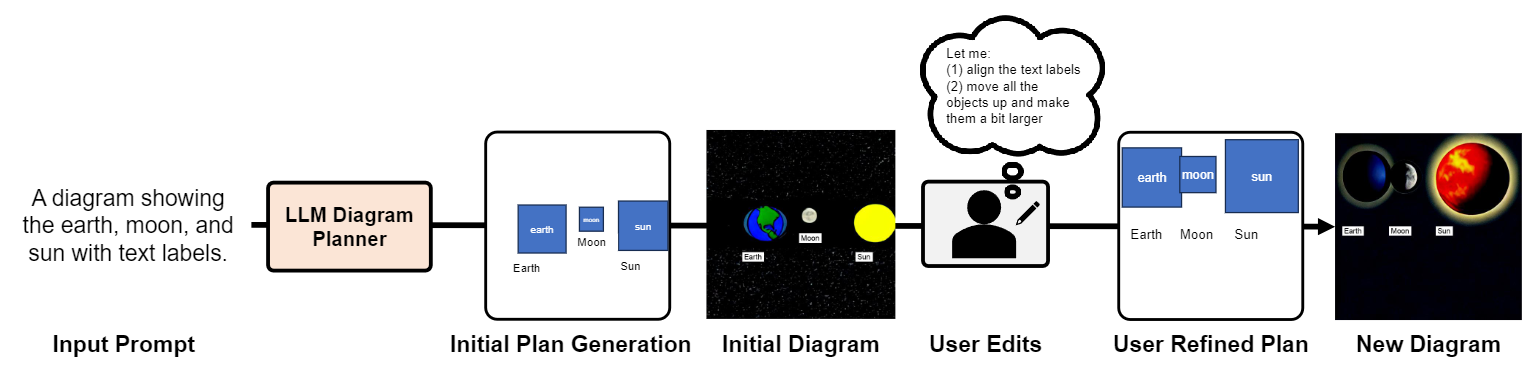
We first generate diagram plans with a planner LLM (GPT-4) via in-context learning. A diagram plan consists of three components: (1) entities - a dense list of objects (e.g., larva in Fig. 2) and text labels (e.g., “egg” in Fig. 2); (2) relationships - complex relationships between entities (e.g., objectobject relationship “[obj 0] has an arrow to [obj 1]” or object-text label relationship “[text label 0] labels [obj 0]”); (3) layouts - 2D bounding boxes of the entities (e.g., “[obj 0]: [20, 30, 14, 14]” in Fig. 2). For object-object relationships, we utilize two types: line and arrow (a line with explicit start and end entities), which are useful when specifying object relationships in diagrams such as flow charts or life cycles. For object-text label relationships, we specify which object each label refers to. For layouts, we use the [x, y, w, h] format for 2D bounding boxes, whose coordinates are normalized and integer-quantized within {0, 1, · · · 100}.
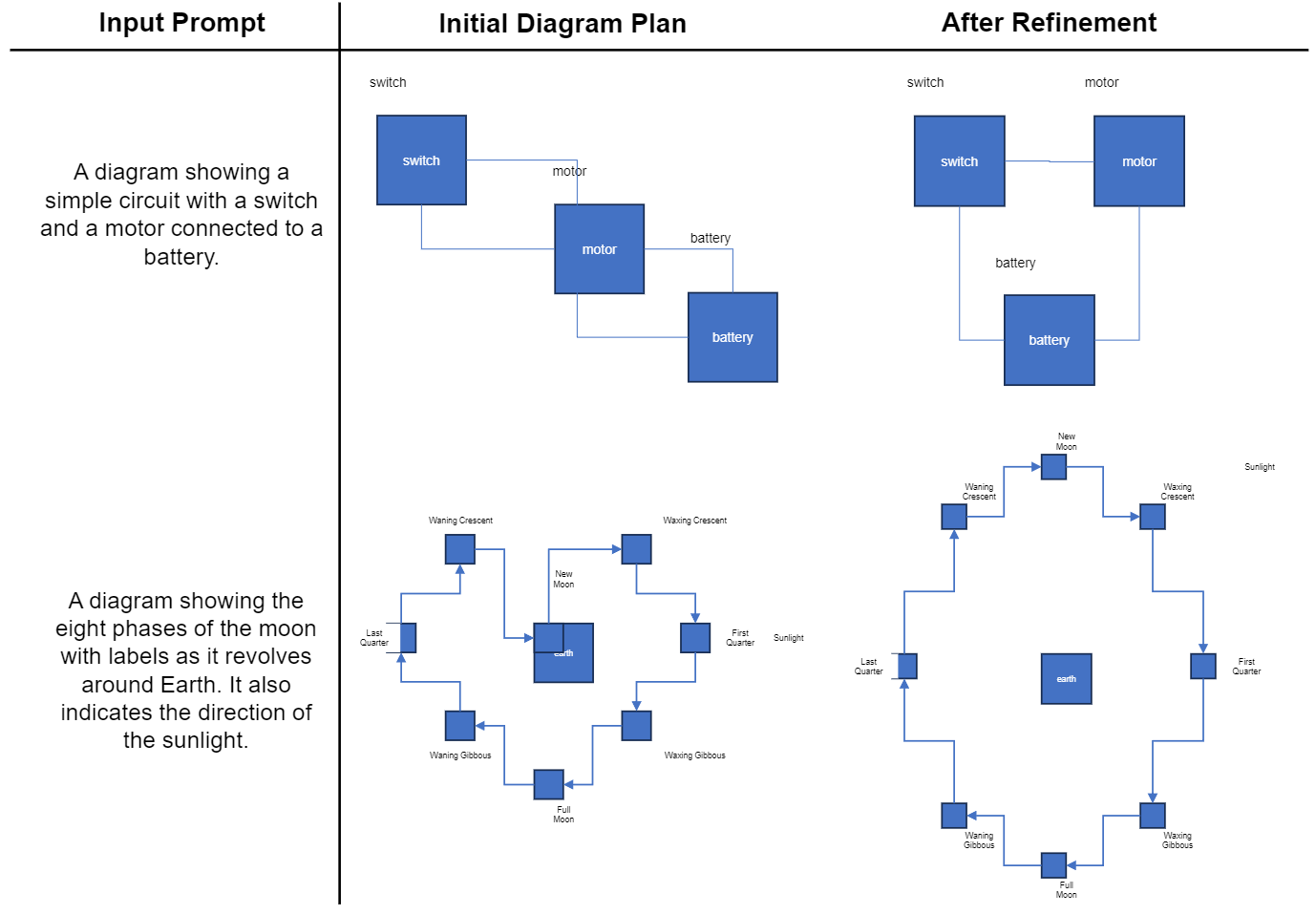
Then, we introduce an auditor LLM that checks for any mismatch between the current diagram plan and the input prompt. It then provides feedback, enabling the planner LLM to refine the diagram plans. Our auditor and planner LLMs form a feedback loop to iteratively refine the diagram plans.
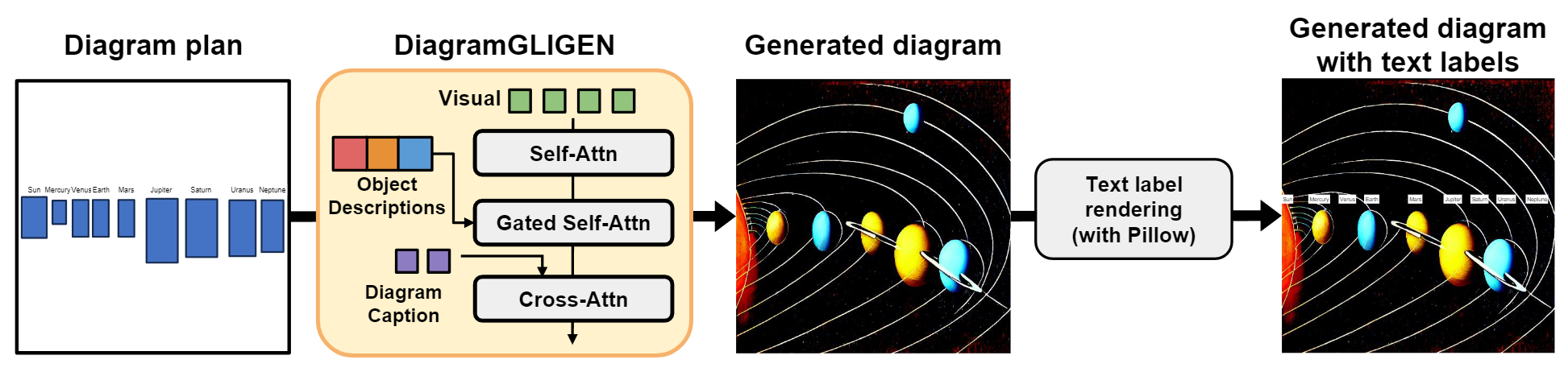
While existing text-to-image generation models demonstrate photorealistic image generation capabilities, in the text-to-diagram generation task, conveying factual information from the text description is more crucial than producing realistic objects. In our experiments, we observe that Stable Diffusion v1.4, a recent strong text-to-image generation model, often omits important objects, generates incorrect relationships between objects, and generates unreadable text labels (see Sec. 5 and Fig. 5). To tackle these issues, we introduce DiagramGLIGEN, a layout-guided diagram generation model capable of leveraging the knowledge of text-to-image generation models while adhering closely to the diagram plans. We train DiagramGLIGEN on our new AI2D-Caption dataset (see Sec. 4.1 for details), which contains annotations of overall diagram captions and bounding-box descriptions for 4.8K scientific diagrams extended from the AI2D dataset.
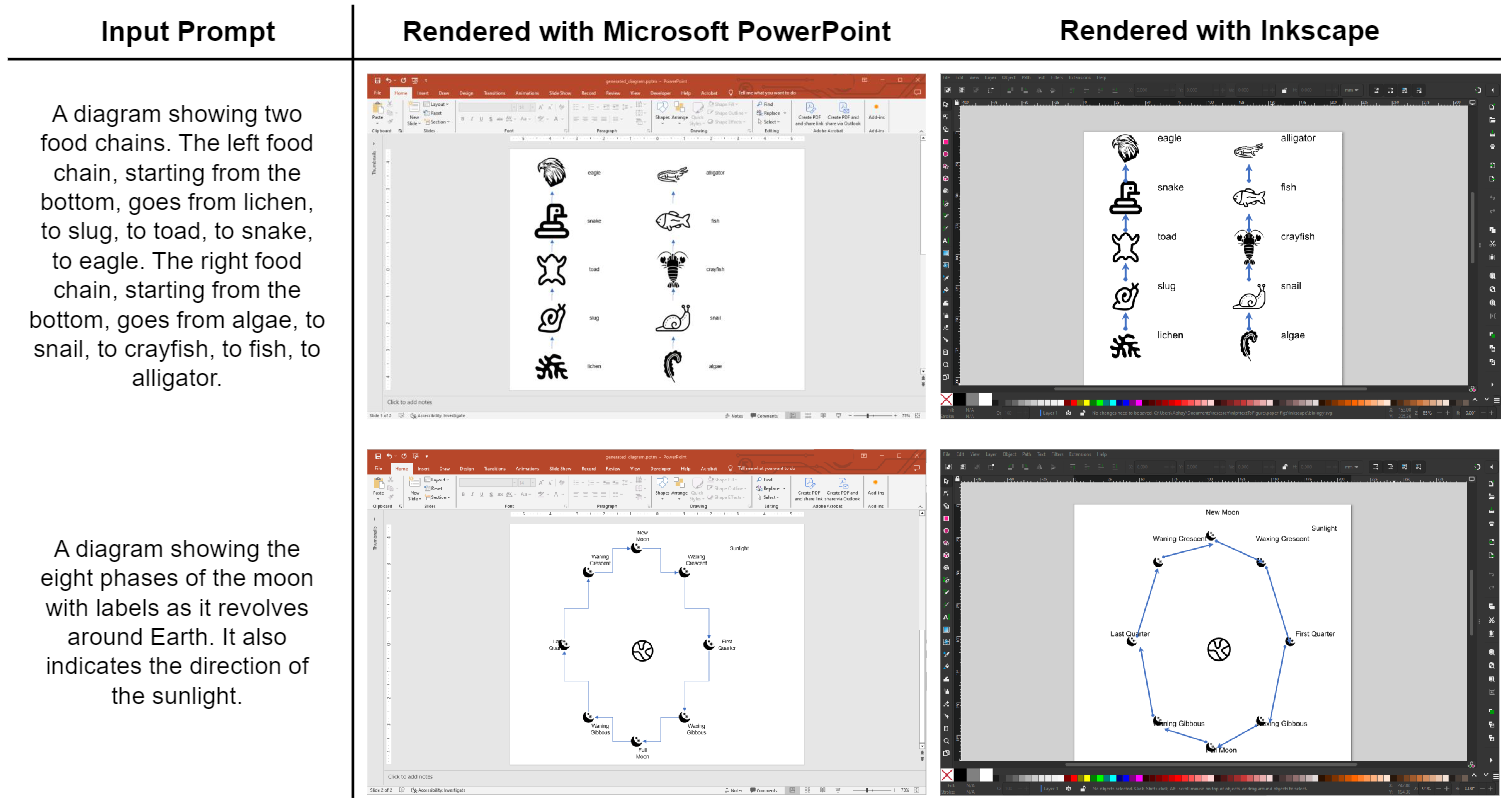
In our diagram generation pipeline, instead of relying on diffusion models for pixel-level generation of text labels, we explicitly render clear text labels on the diagrams following diagram plan with the Pillow Python package.
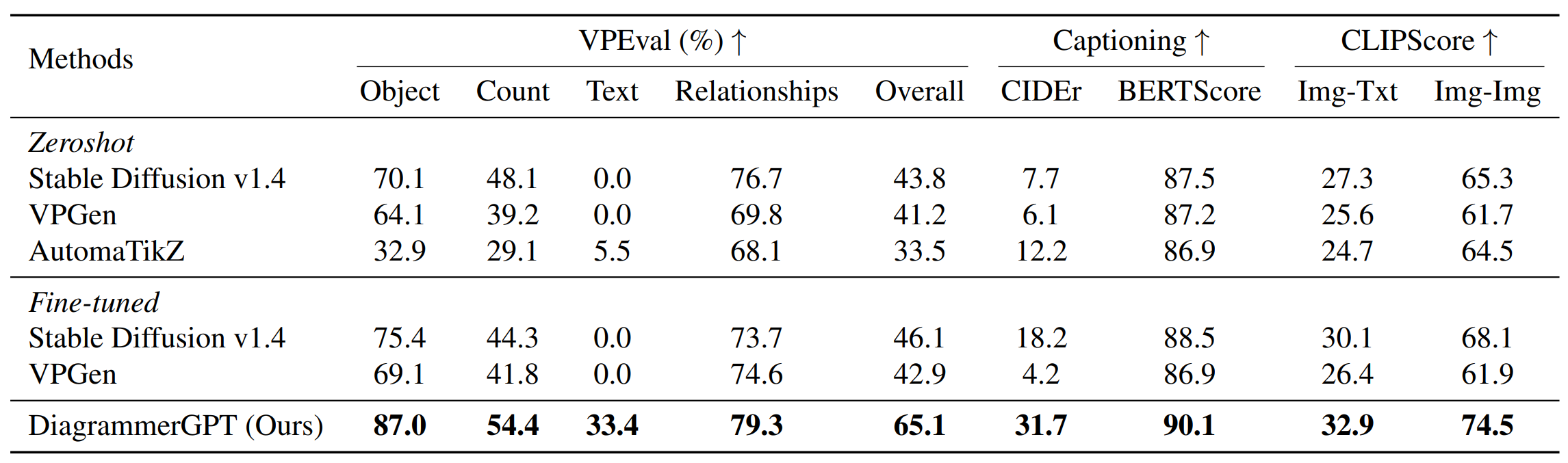
Table 1 left block shows the VPEval results. For both Stable Diffusion v1.4 and VPGen baselines, fine-tuning improves the score for object skill (e.g., 70.1 → 75.4 for Stable Diffusion v1.4, and 64.1 → 69.1 for VPGen), but does not help much or sometimes decreasing scores for count (48.1 → 44.3 for Stable Diffusion v1.4, and 39.2 → 41.8 for VPGen). For relationships, it hurts Stable Diffusion v1.4 slightly (76.7 → 73.7) and helps VPGen (69.8 → 74.6 for). For text, both models achieve 0 scores before and after fine-tuning. Our DiagrammerGPT outperforms both zeroshot and fine-tuned baselines on both overall and skill-specific VPEval scores, showcasing the strong layout control, object relationship representation, and accurate text rendering capability of our diagram generation framework.
Table 1 middle block shows captioning scores (with LLaVA 1.5). Our DiagrammerGPT outperforms both the zeroshot and fine-tuned baselines indicating our generated diagrams have more relevant information to the input prompt than the baselines (which is a critical aspect of diagrams). Our DiagrammerGPT significantly outperforms both fine-tuned VPGen (31.7 vs. 4.2) and fine-tuned Stable Diffusion v1.4 (31.7 vs. 18.2) for CIDEr and also achieves a few higher points on BERTScore.
Table 1 right block shows CLIPScore (with CLIP-ViT L/14). Our DiagrammerGPT outperforms the zeroshot and fine-tuned baselines indicating our generated diagrams more closely reflect the input prompt (image-text similarity) and resemble the ground-truth diagrams (image-image alignment). For CLIPScoreImg-Txt, DiagrammerGPT has slight improvement over fine-tuned Stable Diffusion v1.4 (32.9 vs. 30.1). For CLIPScoreImg-Img, DiagrammerGPT has a larger improvement over fine-tuned Stable Diffusion v1.4 (74.5 vs. 68.1).

As discussed in Sec. 4.4, we conduct a human preference study, comparing our DiagrammerGPT and its closest/the strongest baseline, fine-tuned Stable Diffusion v1.4 in image-text alignment and object relationships. As shown in Table 2, our DiagrammerGPT achieves a higher preference than Stable Diffusion v1.4 in both image-text alignment (36% vs 20%) and object relationships (48% vs 30%) criteria
Our DiagrammerGPT framework is for research purposes and is not intended for commercial use (and therefore should be used with caution in real-world applications, with human supervision, e.g., as described in Sec. 5.4 human-in-the-loop diagram plan editing).
@inproceedings{Zala2023DiagrammerGPT,
author = {Abhay Zala and Han Lin and Jaemin Cho and Mohit Bansal},
title = {DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning},
year = {2024},
booktitle = {COLM},
}